A well-liked open-source Python data manipulation and analysis library is called pandas. It offers the user-friendly functionalities and data structures required to work with structured data with ease. The following are some essential features of the pandas library and their importance:
Data Frame and Data Series:
Data Frame: The Data Frame, a two-dimensional table with
rows and columns, is the main data structure in pandas. It makes it possible
for you to effectively store and handle labeled, structured data.
Series: Any kind of data can be stored in this one-dimensional
labelled array. The fundamental units of Data Frames are series.
Cleaning and Data Preparation:
Pandas offers strong data preparation and cleaning tools. It
has tools for dealing with missing data, rearranging data, and changing the
sorts of data.
To handle missing or inaccurate data, methods like dropna(),
fillna(), and replace() are frequently utilized.
Data Analysis and Exploration: With the use of summary
functions and descriptive statistics, Pandas makes it simple to explore data.
For numerical columns, the describe() technique yields statistical summaries;
for categorical data, value_counts() is helpful.
Pandas makes it simple to group, aggregate, and filter data,
facilitating effective data analysis.
Time Series Analysis: Time series data is well supported by
Pandas. It is ideal for studying time-dependent data since it offers
capabilities for resampling, time-based indexing, and moving window statistics.
Data joining and merging: In data analysis, combining data
from many sources is a frequent operation. Pandas has a number of join and
merge functions, including concat() and merge().
Data Input/Output: Pandas can read and write data in a
number of different forms, such as Excel, CSV, SQL databases, JSON, and more.
Data import and export between sources is now simple as a result.
Flexibility and Performance:
Pandas is made to be user-friendly and flexible. It offers
complex functions for more experienced users, but also makes data manipulation
accessible to newcomers with its high-level interface.
Python is based on NumPy, a high-performance numerical
computing toolkit, internally. This guarantees effective data processing,
particularly with regard to big datasets.
Combining with Different Libraries:
NumPy, Matplotlib, Seaborn, scikit-learn, and other data
science and machine learning libraries in the Python environment are among the
libraries with which Pandas interacts well. A thorough and effective data
analysis procedure is made possible by this flawless connection.
Acquiring knowledge of the Pandas library in Python can be beneficial
for manipulating data, particularly in data science and analysis activities.
Pandas offers a range of methods for data manipulation, cleaning, and analysis
in addition to data structures like Data Frames and Series. Here's a
step-by-step tutorial to get you started learning about pandas:
To get data file, kindly click here:
https://drive.google.com/drive/folders/1O6OFRmHvCEP6KmFDUlEOTuKBAth0K4ao?usp=sharing
.
Install Pandas:
Make sure you have Python installed on your system.
You can install Pandas using pip:
pip install pandas
2. Import Pandas:
In your Python script or Jupyter notebook, import
the Pandas library:
import pandas as pd
3. Data Structures:
a.
Series:
A one-dimensional array-like object. You can create
a Series from a list, array, or dictionary.
student_marks = [67, 28, 83, 64]
s = pd.Series(student_marks)
print(s)
Output:
0
67
1
28
2
83
3
64
dtype: int64
b. DataFrame:
A two-dimensional table of data with rows and columns.
You can create a DataFrame from a dictionary, NumPy array, or
other
data structures.
weather_data = {'Month': ['Jan', 'Feb', ‘Mar’],
'Temp':
[25, 30, 35],
'Town':
['San Francisco', 'New York', 'Los Angeles']}
df_new= pd.DataFrame(weather_data)
print(df_new)
Output:
Month Temp Town0 Jan 25 San Francisco1 Feb 30 New York2 March 35 Los Angeles
4.
Reading Data:
Read data from various sources like CSV, Excel, SQL
databases, etc.
# CSV
df = pd.read_csv('your_data.csv')
# Excel
df = pd.read_excel('your_data.xlsx')
5. Exploring Data:
Useful functions to explore your data:
# Display basic information about the DataFrame
df.info()
# Summary statistics
df.describe()
# Display the first few rows
df.head()
# Display the last few rows
df.tail()
Practice:
import pandas as pd
# To read the CSV file as a dataframe
file_path=('Lucknow_1990_2022.csv')
df
= pd.read_csv('D:\Education Content-2\Apple\Books\pyhthon
folder\Lucknow_1990_2022.csv')
# To get few rows of the DataFrame
print(df.head())
# To get basic information of the dataframe.
print(df.info())
# To display the summary statistics of all
numerical columns
print(df.describe())
Output:
time tavg tmin tmax prcp0 01-01-1990 7.2 NaN 18.1 0.01 02-01-1990 10.5 NaN 17.2 0.02 03-01-1990 10.2 1.8 18.6 NaN3 04-01-1990 9.1 NaN 19.3 0.04 05-01-1990 13.5 NaN 23.8 0.0<class 'pandas.core.frame.DataFrame'>RangeIndex: 11894 entries, 0 to 11893Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 time 11894 non-null object 1 tavg 11756 non-null float64 2 tmin 8379 non-null float64 3 tmax 10341 non-null float64 4 prcp 5742 non-null float64dtypes: float64(4), object(1)memory usage: 464.7+ KBNone tavg tmin tmax prcpcount 11756.000000 8379.000000 10341.000000 5742.000000mean 25.221240 18.795859 32.493405 4.535650std 6.717716 7.197118 6.214145 17.079051min 5.700000 -0.600000 11.100000 0.00000025% 19.500000 12.500000 28.100000 0.00000050% 27.200000 20.500000 33.400000 0.00000075% 30.400000 25.100000 36.500000 1.000000max 39.700000 32.700000 47.300000 470.900000
To get the CSV file used here, click the link:
import pandas as pd
# To read the CSV file as a dataframe
file_path=('Lucknow_1990_2022.csv')
df = pd.read_csv('D:\Education
Content-2\Apple\Books\pyhthon folder\Lucknow_1990_2022.csv')
# To get few rows of the DataFrame
print(df.head())
# To get basic information of the dataframe.
print(df.info())
# To display the summary statistics of all
numerical columns
print(df.describe())
Output:
time
tavg tmin tmax
prcp
0 01-01-1990
7.2 NaN 18.1
0.0
1 02-01-1990
10.5 NaN 17.2
0.0
2 03-01-1990
10.2 1.8 18.6
NaN
3 04-01-1990
9.1 NaN 19.3
0.0
4 05-01-1990
13.5 NaN 23.8
0.0
<class
'pandas.core.frame.DataFrame'>
RangeIndex: 11894
entries, 0 to 11893
Data columns
(total 5 columns):
#
Column Non-Null Count Dtype
--- ------
-------------- -----
0
time 11894 non-null object
1
tavg 11756 non-null float64
2
tmin 8379 non-null float64
3
tmax 10341 non-null float64
4
prcp 5742 non-null float64
dtypes:
float64(4), object(1)
memory usage:
464.7+ KB
None
tavg tmin tmax prcp
count 11756.000000
8379.000000 10341.000000 5742.000000
mean 25.221240 18.795859 32.493405 4.535650
std 6.717716 7.197118 6.214145 17.079051
min 5.700000 -0.600000 11.100000 0.000000
25% 19.500000 12.500000 28.100000 0.000000
50% 27.200000 20.500000
33.400000 0.000000
75% 30.400000 25.100000 36.500000 1.000000
max 39.700000 32.700000 47.300000
470.900000
6. Data Manipulation:
a.
Selection and Filtering:
#
Selecting a column
df['Name']
column_read=df['tavg']
print(column_read)
Output:
0 7.2
1 10.5
2 10.2
3 9.1
4 13.5
...
11889 27.4
11890 28.1
11891 30.3
11892 30.0
11893 27.1
Name:
tavg, Length: 11894, dtype: float64
Output:
#
Selecting multiple columns
df[['Name',
'Age']] #sample code, it is not executed.
column_read=df[['tavg','tmin']]
print(column_read)
Output:
tavg tmin0 7.2 NaN1 10.5 NaN2 10.2 1.83 9.1 NaN4 13.5 NaN... ... ...11889 27.4 25.111890 28.1 26.111891 30.3 26.211892 30.0 28.111893 27.1 24.1 [11894 rows x 2 columns]
#
Filtering rows
df[df['Age']
> 30] #sample code, it is not executed.
filtered_df
= df[df['tavg'] > 20]
print(filtered_df)
Output:
time tavg tmin
tmax prcp
18
19-01-1990 20.5 13.0
29.5 NaN
27
28-01-1990 20.7 NaN
28.8 0.0
28
29-01-1990 21.4 NaN
28.8 0.0
37
07-02-1990 20.7 10.1
25.9 0.0
38
08-02-1990 20.7 12.9
26.1 NaN
... ...
... ... ...
...
11889
21-07-2022 27.4 25.1
33.1 27.3
11890
22-07-2022 28.1 26.1
31.1 16.0
11891
23-07-2022 30.3 26.2
34.7 11.9
11892
24-07-2022 30.0 28.1
34.7 2.0
11893
25-07-2022 27.1 24.1
34.3 0.5
[8577 rows x 5 columns]
b.
Adding and Removing Columns:
#
Adding a new column
df['NewColumn']
= df['Age'] * 2
#sample
code, it is not executed.
#
Removing a column
df.drop('NewColumn',
axis=1, inplace=True)
c. Handling Missing Data:
# Check for missing values
df.isnull().sum()
# Drop rows with missing values
df.dropna()
# Fill missing values
df.fillna(value)
7. Grouping and Aggregation:
# Group by a column and calculate mean
df.groupby('City')['Age'].mean()
import pandas as pd
# To read the CSV file as a dataframe
file_path=('Lucknow_1990_2022.csv')
df = pd.read_csv('D:\Education
Content-2\Apple\Books\pyhthon folder\Lucknow_1990_2022.csv')
# To get few rows of the DataFrame
print(df.head())
# To get basic information of the dataframe.
print(df.info())
# To display the summary statistics of all
numerical columns
print(df.describe())
df_filled = df.fillna(value=0)
OUTPUT:
time tavg tmin tmax prcp0 01-01-1990 7.2 NaN 18.1 0.01 02-01-1990 10.5 NaN 17.2 0.02 03-01-1990 10.2 1.8 18.6 NaN3 04-01-1990 9.1 NaN 19.3 0.04 05-01-1990 13.5 NaN 23.8 0.0<class 'pandas.core.frame.DataFrame'>RangeIndex: 11894 entries, 0 to 11893Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 time 11894 non-null object 1 tavg 11756 non-null float64 2 tmin 8379 non-null float64 3 tmax 10341 non-null float64 4 prcp 5742 non-null float64dtypes: float64(4), object(1)memory usage: 464.7+ KBNone tavg tmin tmax prcpcount 11756.000000 8379.000000 10341.000000 5742.000000mean 25.221240 18.795859 32.493405 4.535650std 6.717716 7.197118 6.214145 17.079051min 5.700000 -0.600000 11.100000 0.00000025% 19.500000 12.500000 28.100000 0.00000050% 27.200000 20.500000 33.400000 0.00000075% 30.400000 25.100000 36.500000 1.000000max 39.700000 32.700000 47.300000 470.900000
# Grouping data by a column and calculating mean
grouped_df = df.groupby('time')['tavg'].mean()
grouped_df
OUTPUT:
time
01-01-1990
7.2
01-01-1991
11.5
01-01-1992
9.9
01-01-1993
14.4
01-01-1994
14.0
...
31-12-2017
12.4
31-12-2018
13.3
31-12-2019
8.4
31-12-2020
9.9
31-12-2021
13.9
Name: tavg, Length: 11894, dtype: float64
# Aggregating data with multiple functions
agg_df = df.groupby('time').agg({'tavg': ['mean',
'sum']})
agg_df
grouped_df.size
OUTPUT:
|
|
||
|
mean |
sum |
|
|
time |
||
|
01-01-1990 |
7.2 |
7.2 |
|
01-01-1991 |
11.5 |
11.5 |
|
01-01-1992 |
9.9 |
9.9 |
|
01-01-1993 |
14.4 |
14.4 |
|
01-01-1994 |
14.0 |
14.0 |
|
... |
... |
... |
|
31-12-2017 |
12.4 |
12.4 |
|
31-12-2018 |
13.3 |
13.3 |
|
31-12-2019 |
8.4 |
8.4 |
|
31-12-2020 |
9.9 |
9.9 |
|
31-12-2021 |
13.9 |
13.9 |
11894 rows × 2 columns
grouped_df.size
OUTPUT:
11894
grouped_df.index
OUTPUT:
Index(['01-01-1990', '01-01-1991', '01-01-1992',
'01-01-1993', '01-01-1994',
'01-01-1995', '01-01-1996', '01-01-1997', '01-01-1998', '01-01-1999',
...
'31-12-2012', '31-12-2013', '31-12-2014', '31-12-2015', '31-12-2016',
'31-12-2017', '31-12-2018', '31-12-2019', '31-12-2020', '31-12-2021'],
dtype='object', name='time', length=11894)
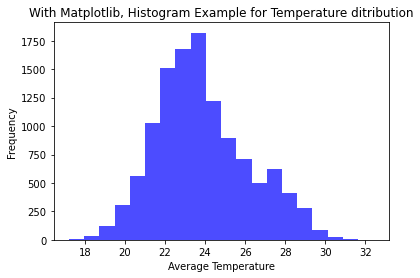
8. Data Visualization:
Pandas integrates well with Matplotlib and Seaborn
for data visualization:
import matplotlib.pyplot as plt
import seaborn as sns
# Histogram
import
matplotlib.pyplot as plt
df['tavg'].hist()
plt.show()
OUTPUT:

# Scatter plot
import seaborn as
sns
sns.scatterplot(x='tmin',
y='tmax', data=df)
plt.show()
OUTPUT:

9. Practice:
#The manager calls the Analytical Engineer to go
through the following data thoroughly and then answer the questions asked.
a)Which day has the highest average temperature? 10-06-2014
b)Which day has the lowest average temperature?
07-02-2008
import pandas as pd
# To read the CSV file as a dataframe
file_path=('Mumbai_1990_2022_Santacruz.csv')
df = pd.read_csv('D:\Education
Content-2\Apple\Books\pyhthon folder\Mumbai_1990_2022_Santacruz.csv')
#To find the maximum average value
tmax1='tavg'
max_value=df[tmax1].max()
print(max_value)
maxvalue_row=df.loc[df[tmax1] ==max_value]
print(maxvalue_row)
#To find the minimum average value
tmin1='tavg' # repeat the same step as done for ‘max_value’
min_value=df[tmin1].min()
print(min_value)
minvalue_row=df.loc[df[tmin1]==min_value]
print(minvalue_row)
OUTPUT:
33.7
time tavg tmin
tmax prcp
8926 10-06-2014 33.7
NaN NaN NaN
17.7
time tavg tmin
tmax prcp
6611 07-02-2008 17.7
NaN 23.2 NaN
How much data is there in this data base, before
and after cleaning the data?
nan_value=df.isna()
print(nan_value)
#drop row which
hold nan value
df_filled=df.dropna()
print(df_filled)
OUTPUT:
time tavg tmin
tmax prcp
0
False False False
True False
1
False False False
False False
2
False False False
False False
3
False False False
False False
4
False False False
False False
...
... ... ...
... ...
11889
False False False
False False
11890
False False False
False False
11891
False False False
False False
11892
False False False
False False
11893
False False False
False False
[11894 rows x 5 columns]
time tavg
tmin tmax prcp
1
02-01-1990 22.2 16.5
29.9 0.0
2
03-01-1990 21.8 16.3
30.7 0.0
3
04-01-1990 25.4 17.9
31.8 0.0
4
05-01-1990 26.5 19.3
33.7 0.0
5
06-01-1990 25.1 19.8
33.5 0.0
... ...
... ... ...
...
11889
21-07-2022 27.6 25.6
30.5 10.9
11890
22-07-2022 28.3 26.0
30.5 3.0
11891
23-07-2022 28.2 25.8
31.3 5.1
11892
24-07-2022 28.1 25.6
30.4 7.1
11893
25-07-2022 28.3 25.1
30.2 7.1
[4623 rows x 5 columns]
Which day recorded the lowest temperature? 08-02-2008
#To find the
minimum average value
tmin1='tmin' #
repeat the same step as done for ‘tmax’ column
min_value=df[tmin1].min()
print(min_value)
minvalue_row=df.loc[df[tmin1]==min_value]
print(minvalue_row)
OUTPUT:
8.5
time tavg
tmin tmax prcp
6612
08-02-2008 17.9 8.5
22.3 NaN
Which day recorded the highest temperature? 16-03-2011
tmax_value='tmax'
tmax_value1=df[tmax_value].max()
print(tmax_value1)
OUTPUT:
41.3
tmax_row=df.loc[df[tmax_value]==tmax_value1]
print(tmax_row)
time tavg
tmin tmax prcp
7744 16-03-2011 32.8
19.2 41.3 NaN



.png)
.png)